In a recent blog post, I showed how easy it is to monitor a leaf and spine data center with NetBeez agents. I would like to write more about the importance of network latency measurements in large-scale data centers. For this purpose, I would like to mention a paper that was presented by a group of engineers from Microsoft at Sigcomm 15.
Microsoft’s data centers are huge and complex environments that support thousands of servers from which services are distributed and have complex dependencies and need network connectivity. In this environment, software and hardware failures are the norm rather than the exception. As you can imagine, it is very difficult to support this massive infrastructure if you don’t have data on network latency.
Challenges of large-scale data centers
Every day, Microsoft engineers and support operators face many challenges. First of all, when a performance issue arises, it has to be determined whether it’s a network issue or not. For example, they have to be able to quickly understand what caused an end-to-end latency increase to the 99th percentile or throughput to decrease from a 20 Mbps baseline to a 5 Mbps. According to the writers, 50% of the problems are not caused by the network, however, without data, how can they prove that?
The second challenge is to define and track service level agreements (SLAs). SLAs are very important, for example, to those services that, like a search query, include thousands of servers. In this case, the query execution time is determined by the response of the last server. Because this service is very sensitive to network latency and packet drop, measuring and enforcing SLAs for those two values is very important.
The third challenge is to quickly troubleshoot network problems when failures cause live-site incidents. To quote the paper, Microsoft’s data centers “have hundreds of thousands to millions of servers, hundreds of thousands of switches, and millions of cables and fibers.” In this infrastructure, finding the smoking gun is not easy and a fault isolation system is needed.
An important factor to consider that increases troubleshooting complexity is equal cost multipath (ECMP). ECMP is a technology that is extensively used in modern leaf and spine datacenters to load-balance traffic across multiple parallel links. However, since ECMP uses the TCP/UDP five-tuple to load-balance traffic across different links, it makes it very difficult to locate a faulty spine. Active monitoring traffic is needed to detect and locate silent packet drops and black holes.
So what’s the solution?
Pingmesh
Microsoft engineers developed Pingmesh, a “large-scale system for data center network latency measurement and analysis”. Pingmesh creates three separate graphs of network latency generated by TCP and HTTP pings. The first graph depicts the relationship between servers in a rack, the second covers the top-of-rack (ToR) switches, and the third one within an individual data center. With this information, when a live-site incident event happens, it makes it easier to determine if the performance issue is caused or not by the network.
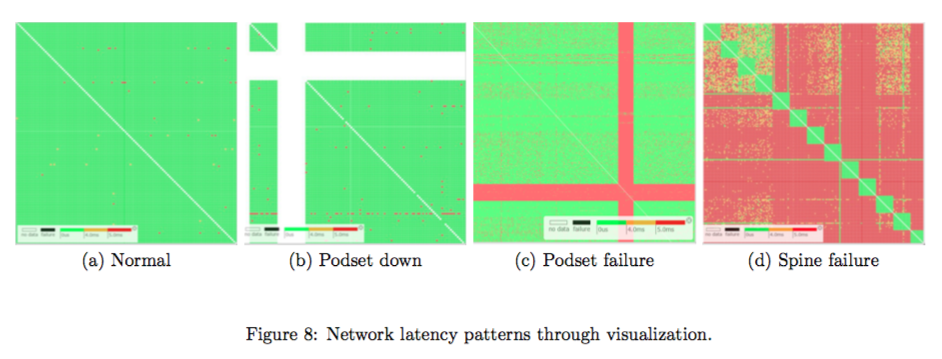
Thanks to the data offered by Pingmesh, network engineers can easily troubleshoot and locate source of problems such as packet drops or latency increases.
Similarities to NetBeez
The network monitoring implementation of NetBeez has strong similarities to Pingmesh. If you read the entire paper, you will find similar components in our system: an agent layer, a controller, and a data repository that includes an analytics engine. For those familiar with NetBeez dashboard, creating a full-mesh of ping and traceroute tests in NetBeez is easy and the resulting visualization is very similar to one offered by Pingmesh.
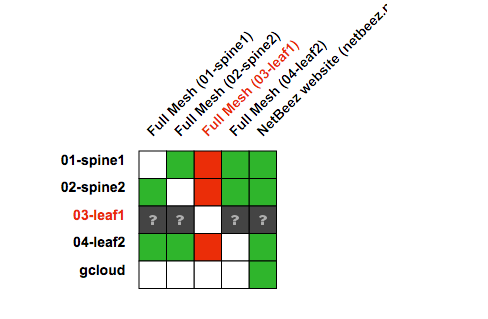
Other features described in the paper and implemented in NetBeez include, for example, the capability of generating performance alerts based on SLA, an always-on service, and software agents that can run on commodity Ethernet switches as well as Linux-based servers.
If you want to learn more about NetBeez and discuss a potential deployment with us, I will be happy to schedule a demo with you.