We are moving past the era of needing dedicated circuits for enterprise WAN networks. Connectivity is becoming a commodity, and since many applications run on the cloud or rely on access to the cloud, we don’t need private circuits to reach them. WAN connectivity is becoming commoditized and this creates new controllability and visibility challenges for network engineers.
Network Controllability
More and more enterprises are structuring their networks to look like this:
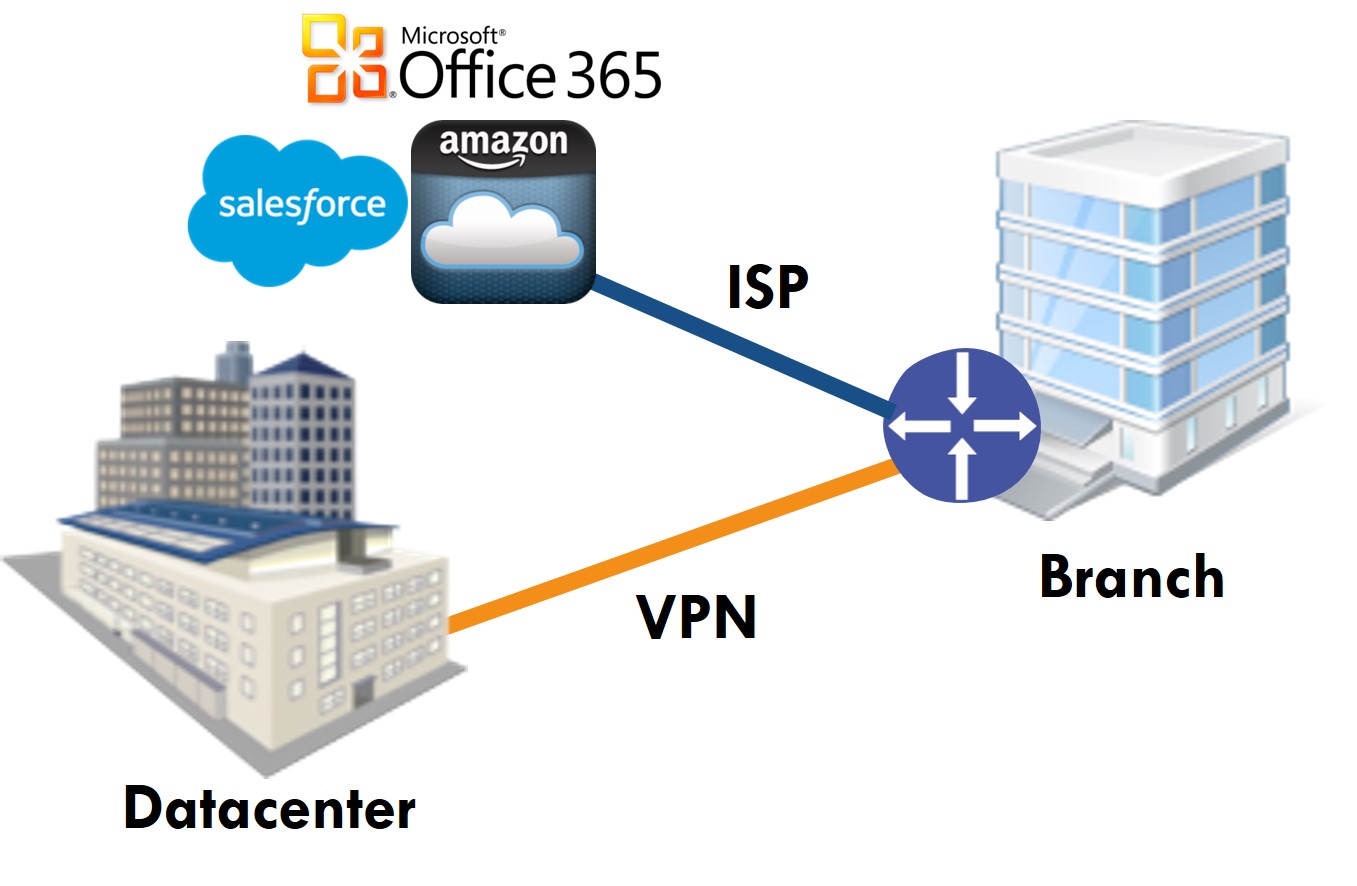
Employees at branch offices use local ISPs to reach the Internet and SaaS applications they need to get their job done. In order to reach a private datacenter, they use a VPN tunnel. Both of these connections go over one or more ISPs, which provide their services with zero controllability into their internal circuits.
If there is a connectivity or performance issue that you think falls under the jurisdiction of the ISP, then all you can do is open a ticket and wait for the resolution. That’s where SLA agreements kick in – you expect certain number of nines in terms of availability and timely resolution when something goes wrong.
With this architecture, the only control you have is at the end points of the network, i.e. the datacenter and branch offices. You can control things such as having multiple ISPs to avoid a single point of failure and a reliable crossover, and that’s about it. For example, if you were using only DynDNS servers you would have experienced a failure during last week’s DDoS attack. If you had a backup DNS service, you would have merely experienced a performance degradation or just a much shorter outage.
Obviously, everything comes at a price: MPLS circuits are more expensive, but are dedicated lines that let you control things like the quality of service. VPN is cheaper, but you don’t get all the MPLS benefits.
Network Visibility (aka Monitoring)
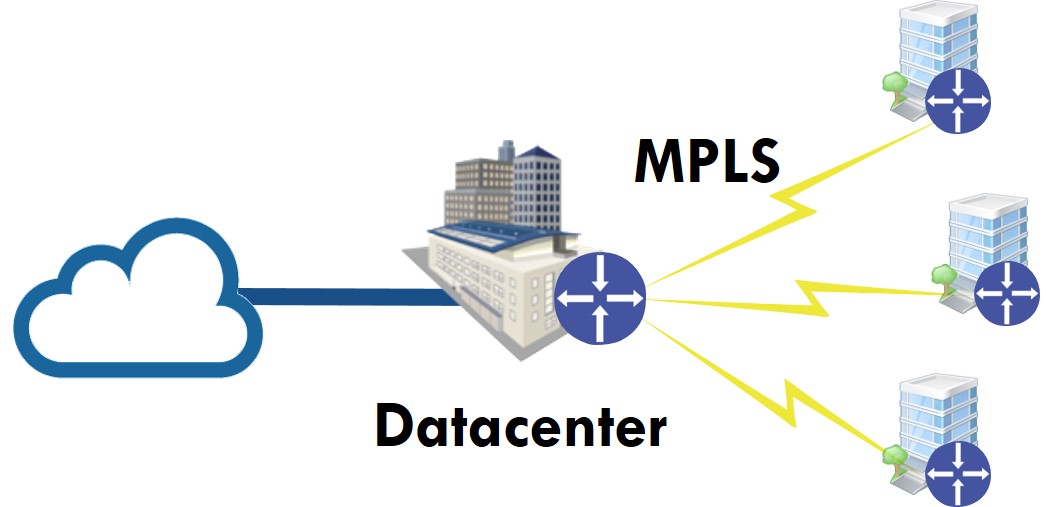
Traditional hub-and-spoke architecture can give you the full picture of the network traffic from remote branches to the Internet and any other destination since everything goes through the datacenter.
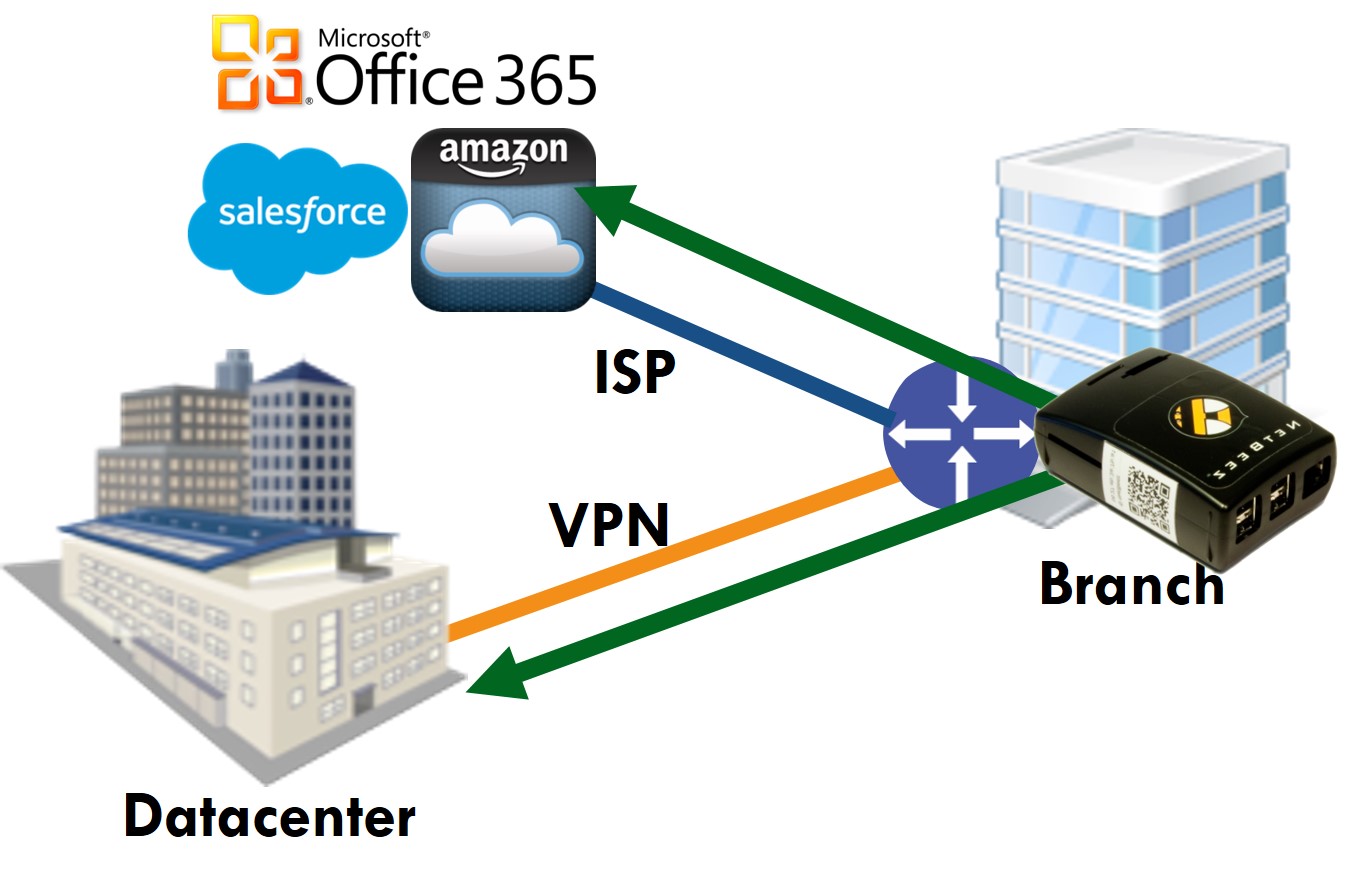
The split-tunnel architecture we covered above poses some challenges: since the traffic to the Internet doesn’t go through the datacenter, but directly to an ISP connection we don’t know what the user experience is at remote branches.
Supporting remote users may looks like this:

This is a frustrating situation for both the employees and the help desk or the network engineers. The source of frustration is lack of visibility.
Wouldn’t it be great if there was a dedicated employee per branch browsing the Internet and critical business applications who would notify us if something went wrong and also provide us with detailed historical information about the problem?
This is what real-user monitoring does in an automated way. Dedicated agents at each branch capture the user experience and report that information, enabling easy detection of anomalies and quick resolution of issues.
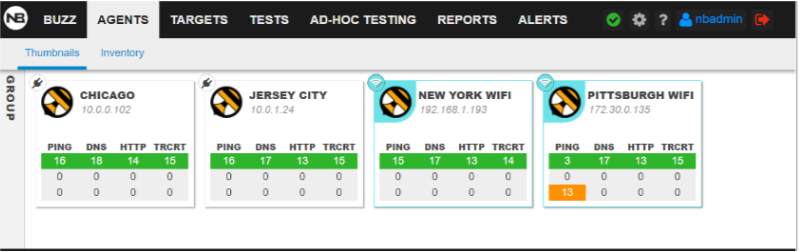
For example, on the NetBeez dashboard below we have four agents monitoring real user experience at our branches in Chicago, Jersey City, New York, and Pittsburgh, with the New York and Pittsburgh agents monitoring the wireless performance. While everything looks normal for the first three, there are some performance issues with the Pittsburgh wireless as denoted with the orange alert.
One of the most important benefits of real user experience monitoring is proactive detection: you don’t have to wait for users to open a ticket to bring issues to your attention. You can know about the issue within seconds and also have reliable data to troubleshoot it (rather than vague, imprecise user-submitted reports).
The networking arena hasn’t shied away from constant change and innovation. If we have a gap between the adoption of new networking technology and the tools that manage and monitor them we will be left behind. Real user monitoring is here to address a gap in the network monitoring space, and we’ll see it getting more and more prevalent in the next few years.




