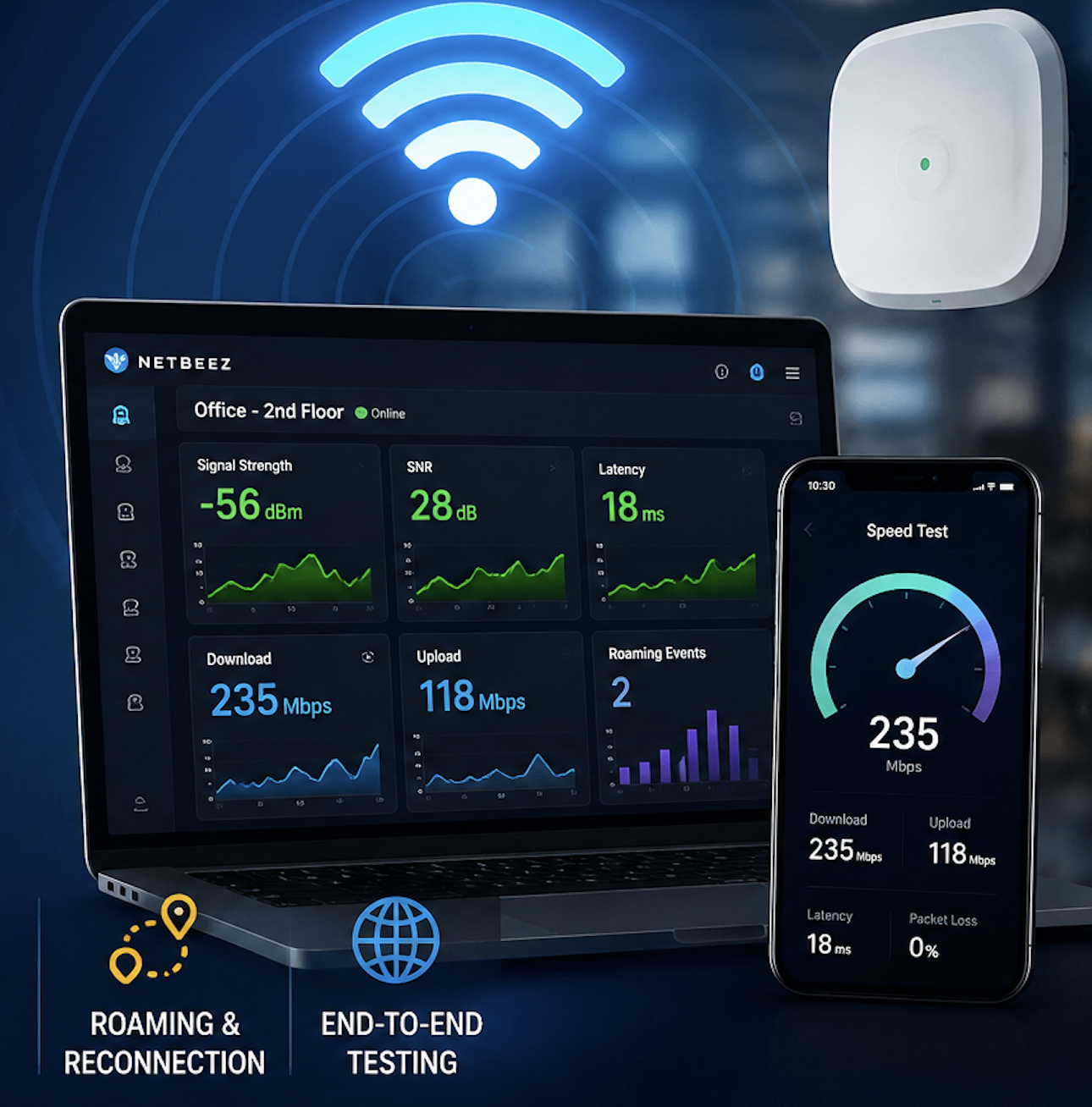
Most of medium to large companies have three levels of escalation of trouble tickets:
Most of medium to large companies have three levels of escalation of trouble tickets:
Help Desk – The first level is generally handed by the help desk (or service desk) that receives and processes user reported outages via phone or other communication means. Before opening and escalating a ticket to higher levels, the help desk personnel have no other way to gather information about the scale of the outage other than wait to receive two or more calls from different users reporting the same problem. As you can imagine, this process is inefficient, time consuming, and reactive. The information provided by the users is oftentimes inaccurate and imprecise and, consequently, the help desk has no valuable information on what group the ticket should be escalated to.
Network Operations Center (NOC) – The second level is generally handled by the NOC operators that, if needed, notify affected users and the company’s management about the outage. The NOC operators will also provide some degree of first response and analysis. Most of the tickets processed and fulfilled at this level are escalated to a third party, such as solution vendors, Internet service providers, and cloud service providers. Tickets that don’t fall into this bucket are forwarded to the level 3 analysts or specialists.
Level 3 or Specialists – The third level is serviced by the on-call specialists, either network engineers, system analysts, security experts, or application developers that provide the higher level of technical support. Members of this group may have designed, implemented or just manage on a day-to-day basis a specific area of the IT infrastructure. Tickets are escalated to this level because one or more components managed by that group require administrative attention due to a hardware failure, software misconfiguration, or irregular behavior. It may just happen that the specialist has to investigate whether or not the systems are the cause of the outage that is affecting the users. This is the case where the lack of tangible data or precise information by the users and help desk further delays the ticket’s resolution. In this case scenario, the troubleshooting efforts may involve more than one level 3 groups and the finger pointing starts until the root cause of the issue is found and fixed.
Medium and large IT infrastructures are complex systems with many moving parts: To successfully troubleshoot remote application issues is extremely important to get real data about network and application performance. Especially when business critical applications are affected, it is necessary to proactively detect the scale of the problem and understand which component within the infrastructure is disrupting your users. This data will enable the help desk, the NOC operators, and the level 3 groups to successfully collaborate on a timely resolution of the network or application issue.
There’s lots of room for improvement and innovation in this area of network management, and that’s one aspect to which we’ve taken an interest. NetBeez aims to improve customer support operations in the detection and troubleshooting phase by means of improved data gathering on network and application performance, and streamlined diagnostics through improved user interface design and data processing.
In our recent paper, “Troubleshooting Internet Outage With and Without NetBeez”, we discuss ways to streamline ticketing, automate troubleshooting steps, better share information, and hopefully remove manual steps, errors, and other headaches. The paper covers troubleshooting methods that can be implemented whether or not you have NetBeez.
We’d love to hear from you about what steps you take to streamline help desk operations at your organization and any other comments and suggestions.