Imagine not being able to connect to a website. How do you troubleshoot such a problem?
Most likely, you first try to ping it and then work yourself up the stack. You check if your workstation can resolve the IP address of the fully qualified domain name, if you can connect to the default gateway, and if your local gateway can reach the border router. If everything up to the border gateway works, then it could be something outside in the Internet. First, you want to make sure that your border router’s uplink connection to your service provider is active and passing traffic. If that works, then it could be a routing problem between your provider and the destination. If that’s not the case, it could be that the website itself is down.
A quicker way to identify where the failure is between your workstation and the destination is to use the traceroute command. Traceroute, as everybody knows, performs a hop-by-hop path analysis to a specific IPv4/IPv6 destination. It’s clear that, with these two commands, a lot of troubleshooting can be accomplished.
For this reason, NetBeez includes both commands in its agents because, for engineers that have to support a Wide Area Network with many network locations, those commands are a must-have. So let’s see how you can include these tests when you create network-monitoring targets within NetBeez.
Internet Connectivity Target
In this example, I created a target and included ping and traceroute tests to some well-known Internet websites to verify that WAN locations have connectivity to the Internet and good performance.
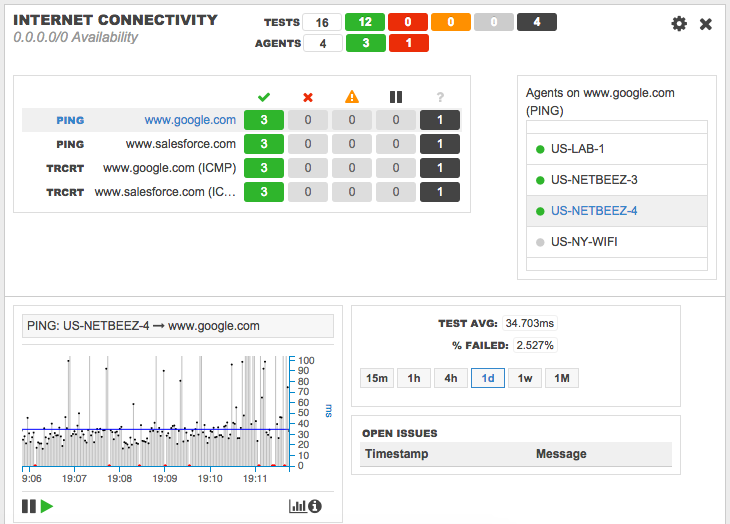
Thanks to this target, I can:
- Detect loss of connectivity to the Internet from all my network locations within 30 seconds; if I want to be aggressive I can decrease this time to five seconds.
- Detect routing changes that can have an impact on application performance (check out my previous blog post, which shows a use case on this regard).
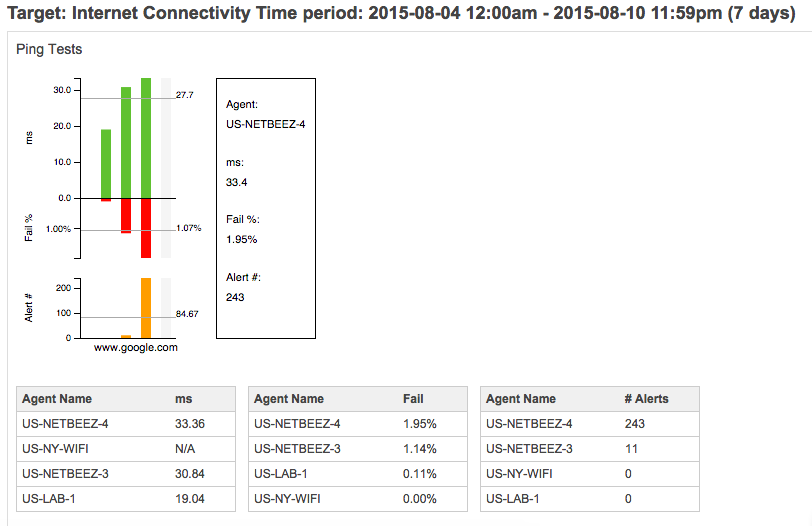
- Create a baseline for network performance and location uptime as shown in this weekly simple report for three locations.
Full-mesh Network Monitoring Target with Ping and Traceroute
The full-mesh target is appropriate for monitoring end-to-end latency and packet loss amongst WAN locations that exchange voice-over-IP calls or have other user-to-user applications. In this example, I created a target and included seven agents that, installed at different sites, perform ping and traceroute tests with each other.
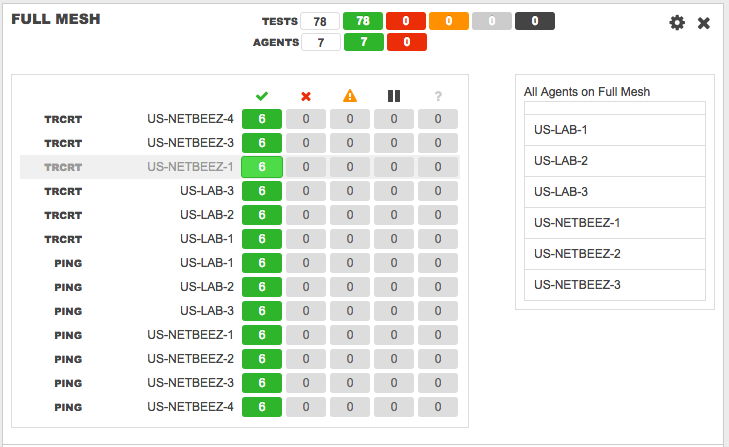
The benefits of this target are simple:
- Detect routing issues between locations that can cause connectivity or performance degradation issues to the applications.
- Generate a baseline in terms of hop count, round-trip-time, and packet loss.
Closing remarks
It’s clear that ping and traceroute tests are very useful in a distributed network monitoring environment. However, the network engineer should also be aware that both commands have some limits and, for this reason, adjustments may be required during their setup. For example, ping tests may be assigned to a low priority Quality-of-Service class. The good news is that, with the August release of NetBeez, you can assign a specific ToS value to ping tests. Another case is with the traceroute command, which can use ICMP, TCP, or UDP as protocol. We have noticed that in some cases, the same traceroute test with one protocol fails because it reaches the maximum number of hops, while in using another protocol the same test succeeds. Also in this case, test your setup before the final configuration.
I hope that this article was beneficial in understanding how ping and Traceroute tests can be integrated with your monitoring targets to quickly detect network issues and identify their root causes before they impact your end users. If you want to learn what network metrics impact throughput and end-user experience, I recommend you to download our end-user experience guide.