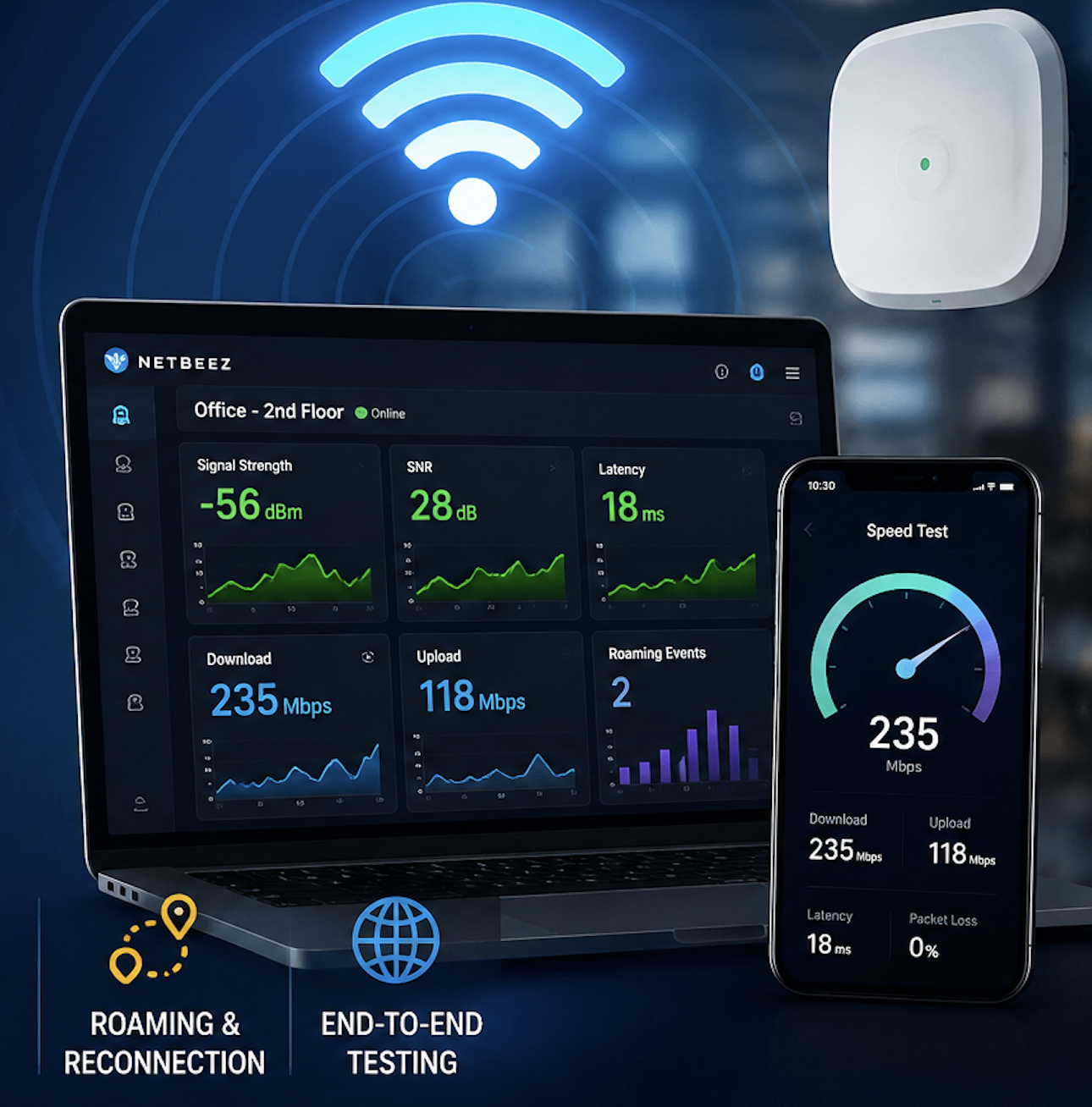
If you don’t measure it, you can’t manage it.
This quote aptly applies to the art and science of administering an enterprise network. Managing an enterprise network is not just about doing design and deploying network equipment, it also entails end-user support and incident response. Companies whose design and operations groups don’t communicate nor use common performance monitoring tools will have a hard time providing quick response to incidents and will lose many man-hours to troubleshoot issues that affect the end user.
Generally, network architects and engineers who designed the infrastructure have the necessary knowledge of the infrastructure to select and configure the monitoring tool that can best enable the support team in providing quick detection and incident response.
Let me bring up some examples of how measuring network availability and performance from the end-user perspective can save time in the detection and resolution of network problems, improving performance and availability. Performance network monitoring tools can empower help desk operators to address more problems without having to rely on escalation to higher levels or on spending time over the phone with the end-user to request information needed to troubleshoot the issue.
With NetBeez, wired or wireless monitoring agents are physically installed at remote locations to continuously gather network and application performance information. Without real-time and historical data of network and application performance from the remote user’s perspective, when an issue arises, the help desk operator will have to gather this data himself in different ways: through remote desktop connections, by accessing the CLI of remote routers and switches, and sometime even dispatching an engineer at the remote office to perform some on-site assessments.
Localized performance issues
Discovering local network performance issues is pretty simple when you have PING data from all your remote locations.
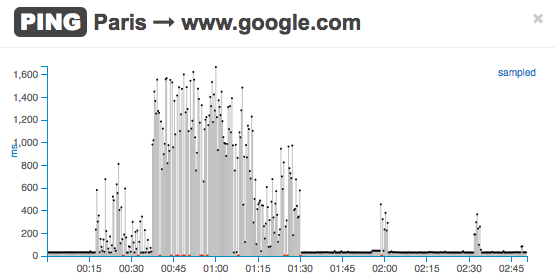
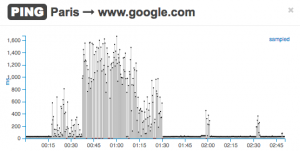
Here is an example of two locations, Paris and Hague, with different network performance, as shown in these two real-time plots of PING tests to www.google.com. Users in Paris have experienced slowness between 00:15 and 1:30.
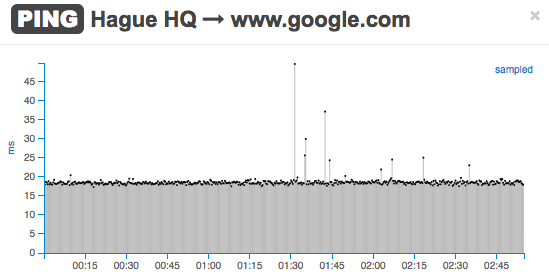
Meanwhile, the network performance at the Hague location is good as there is no packet loss nor increase in network latency.
Application Performance Issues
According to the Microsoft engineers that worked on the Pingmesh project, in 50% of cases, application slowness is not caused by the network, but by the application’s components themselves. But how can network engineers prove that without proper data?
Here’s another example: your team is troubleshooting sporadic performance issues with a cloud application. It is clear by looking at the PING and HTTP tests from an agent located in New York City that the cause of slowness is with the front-end web server. In fact, the PING tests are stable …
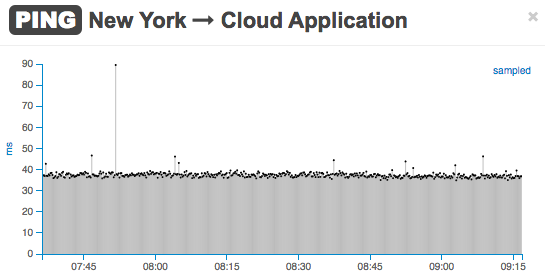
… while, for just under 15 minutes, the HTTP GET time increases five-fold.
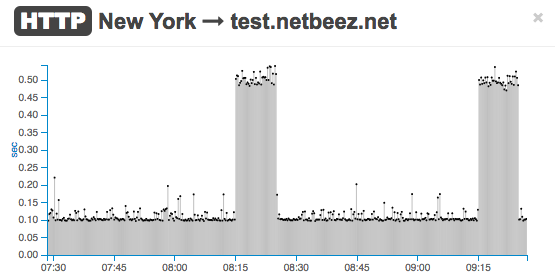
Conclusions
When simple tests like PING and HTTP are paired with a system like NetBeez, their measurements can reveal a lot of useful information to reduce detection and troubleshooting time of network and application performance issues. If you would like to test NetBeez request a demo or free trial.