In a perfect world, telecommunication networks have 100% uptime, low latency, and high bandwidth. In reality, each one of us deals with slow applications, choppy calls, and unreliable connections. In WiFi networks, this is even more frequent.
Yet, providing a good end-user experience is possible. Detecting problems before users do is not a fortune teller’s trick, but something that can be achieved with the right tools and processes in place. So how can Network Engineers achieve Zen for their networks?
Here are three main points that are critical to ensure a great service to your network users:
Detect performance issues before they turn into outages
A monitoring solution that actively verifies network performance with ping tests can quickly alert if degradations occur. This system continuously compares the monthly historical average of latency and packet loss, which can be taken as baseline of network performance, to the the 15 minute or 1 hour value. As soon as the short term average deviates from the baseline, an alert is triggered.
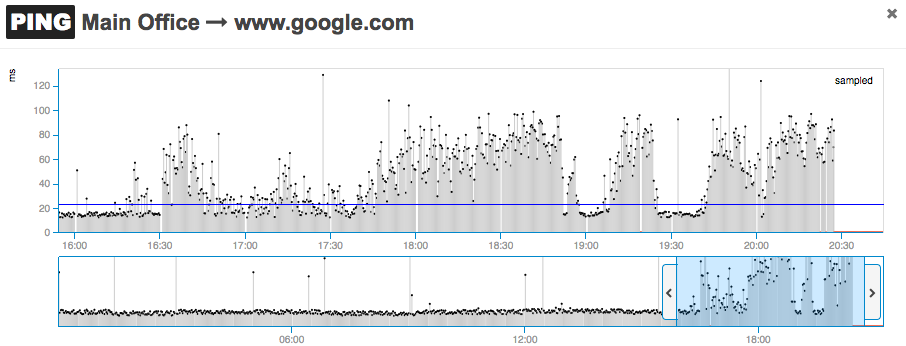
For example, the following graph clearly demonstrates how an increase in network latency can be detected before it leads to a complete network outage at a remote location:
Validate network configuration changes
Many network changes are performed outside of regular business hours to reduce the risk of affecting the end-users. Yet many network outages are still caused by poorly planned configuration changes. The typical scenario is where the Network Engineer applies a change at 2 a.m. At 8 a.m., when the first users start logging into their workstations, they can’t access some or all applications because of the network change that was pushed a few hours before.
A way to avoid these unneeded outages, is by properly validating network changes. This requires, for example, making sure that all remote locations can access Internet and intranet applications as they did before the change. This task can be easily done with an SSH or RDP connection to hosts located at remote locations. However, this manual check is not easy to implement in a network with dozens, hundreds, or thousands of remote locations. It can only be accomplished with a distributed network monitoring and testing solution. If you want to read more about this topic, you can read the blog post on configuration changes validation I wrote couple of years ago.
Use high-frequency tests
High-frequency tests enable you to quickly detect problems before users calls the help desk. An SNMP server that polls MIB information every 5 minutes (300 seconds) can’t get the same results of a ping test with a 5-second interval. The sooner an outage is detected, the sooner it can be troubleshooted and fixed.
I hope this short article provided some useful tips on how to provide an excellent end-user experience, detecting problems quickly, and reducing service downtime. If you’d like to connect with me, or continue the discussion, feel free to request a demo or share your comment below.