Network Engineers are Impaired by Lack of Network Monitoring
In recent months, I have had several conversations with many network engineers to get their perspective on enterprise networks, network monitoring, and troubleshooting. These interactions were very beneficial for learning how much time they spend troubleshooting, which tools and procedures they use to troubleshoot network and application issues and to understand the recurring problems they deal with.
I’d like to present the data I collected interviewing 25 network engineers that work with multi-site networks. Based on these findings, I would also like some advice to network engineers on how they can improve their network operations, reduce time spent troubleshooting, and therefore network downtime, and make the best use of their skills and time.
Finding #1: Engineers spend a considerable amount of time troubleshooting
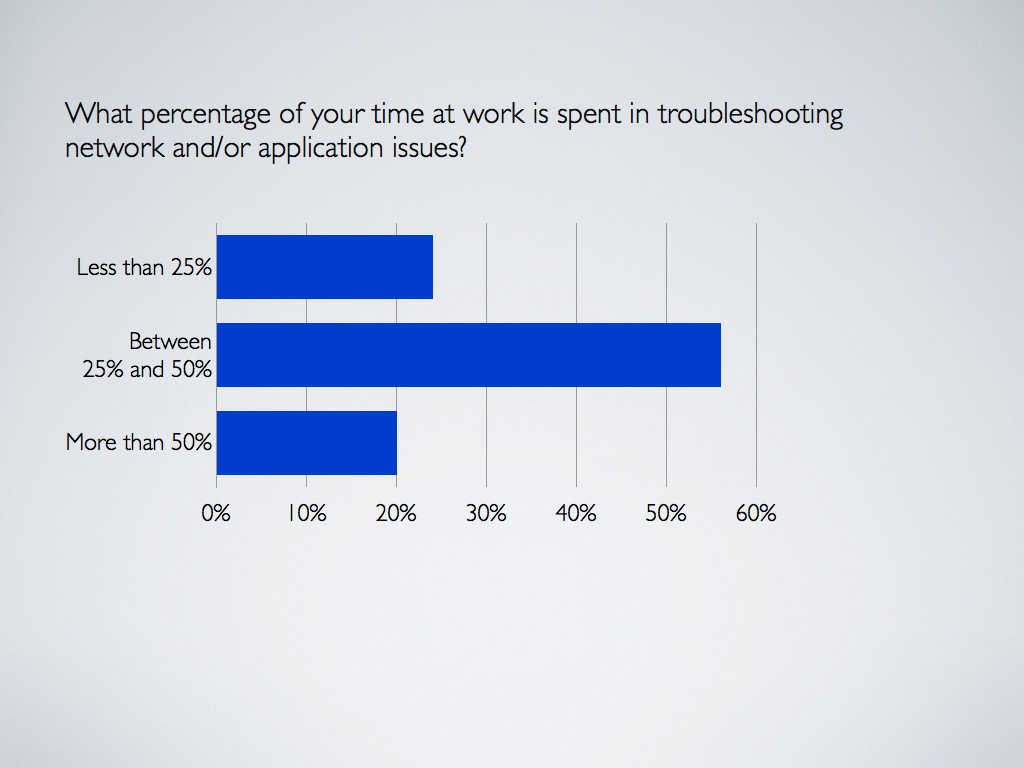
As you can see from the graph above, more than 70% of network engineers spend more than 25% of their time troubleshooting network and/or application problems. The primary responsibility of a network engineer should be to build and operate an enterprise network and provide higher-level escalation support. As you can imagine, it’s disruptive and not efficient for a network engineer to spend 25% of his time or more troubleshooting, because this time is taken away from projects that aim to build, tune, and optimize the network. Improving network operations means having network engineers spend less than 25% of their time troubleshooting and providing customers support.
Finding #2: Engineers rely too much on help desk data and on Command Line Interface commands on network hardware
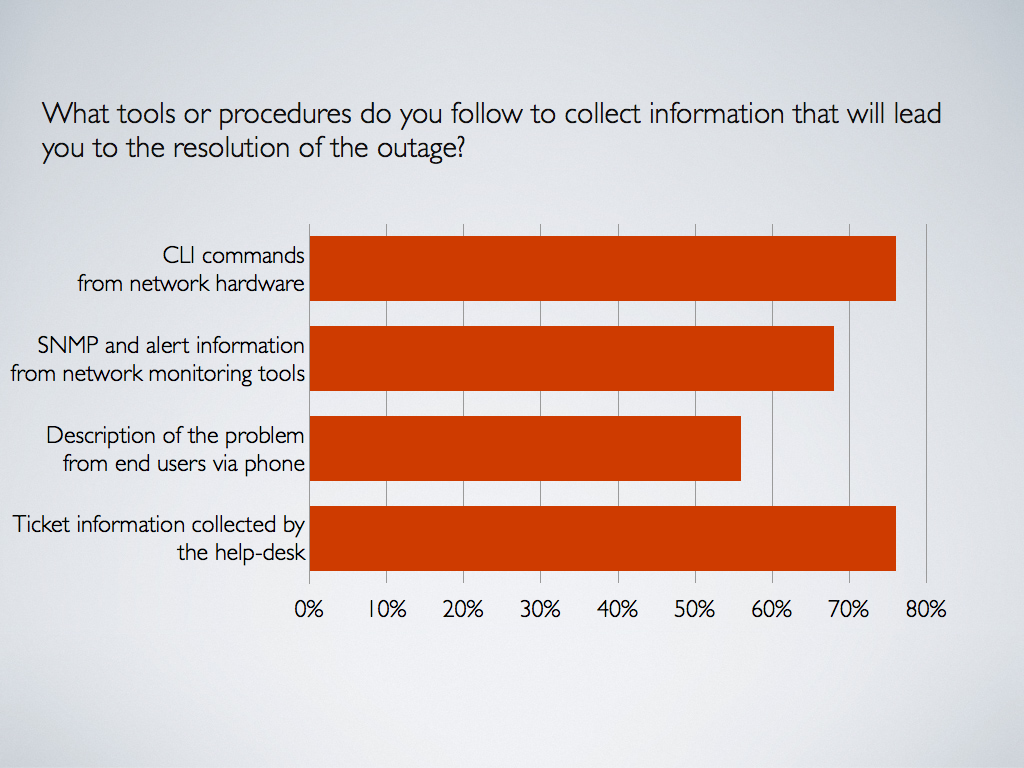
The problem that I see here is that SNMP and alert information received from network monitoring tools only appear as the third method in resolving network and/or application problems. As you can imagine, the two primary methods, trouble tickets and command line interface commands, are not efficient for troubleshooting and resolving network and application problems. Trouble tickets are not efficient because end users report inaccurate and imprecise information. CLI commands output from network hardware take a considerable amount time, as network engineers have to connect to routers and switches and run the commands one by one and, oftentimes, this process has to be repeated at multiple network locations. Another major problem with CLI commands is that they lack of historical data, making it even more difficult when the network engineer is troubleshooting sporadic network and application issues.
Finding #3: Network engineers are engaged in troubleshooting efforts even when the network is not the problem
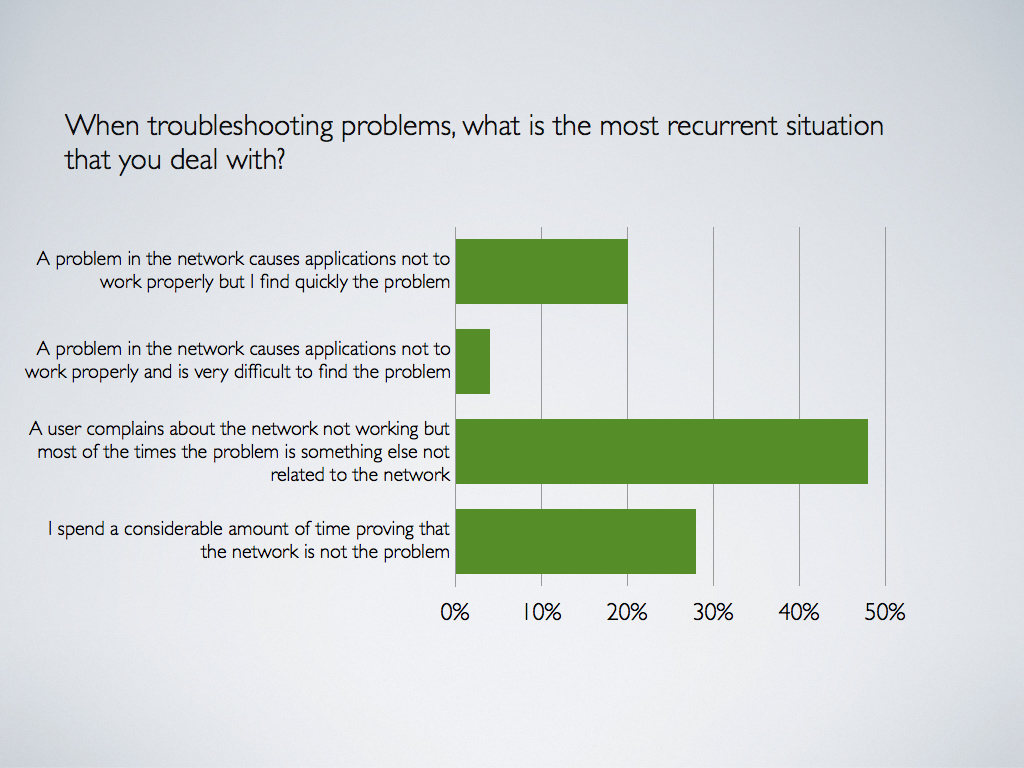
The result to this question may not surprise most network engineers, because even when the smoking gun is not the network, they still need an alibi. The process of collecting data showing that the network is not the cause of application issues takes as much time as, or even more than, troubleshooting a real network problem. Delays in the collection of such data has two consequences: first of all, network engineers are wasting time troubleshooting problems not related to network issues, and, second, it delays the resolution of application issues.
Three Simple Recommendations
So how can network engineers make their lives easier, reduce the amount of time they spend troubleshooting and, at the same time, decrease resolution time of network and application outages?
Here are my recommendations on how network engineers can improve their operations:
- Power to the service desk operator – Adopt a network-monitoring tool that can be used by network engineers as well as service desk operators. The data offered by such tool should be simple to interpret and effective so service desk operators can process tickets that otherwise would be escalated to network engineers.
- Everything in one place – Collecting information from network hardware is not efficient, especially if your network is distributed across dozens or hundreds of network locations. Distributed network monitoring is the answer, thanks to agents deployed to each location. You can rely on the necessary coverage you need to get the complete picture of your network when troubleshooting. Such a solution must provide a dashboard that displays all the information collected by all the agents deployed.
- Remember the past – Your tool should keep historical data that is easy to retrieve, consult, and export. Such data should be in the form of what applications and services network users were able to access, with what performance and if an outage happened, how long it lasted. Such data will be vital in promptly providing root cause analysis reports to show whether or not the network affected this or that application.
I hope that this post was beneficial for better understanding the types of challenges that face the majority of network engineers. I would like to hear your feedback on this, so please feel free to comment.
Do you want to learn more about NetBeez and distributed network monitoring? Get a 30-day trial or watch our latest webinar.




