When an IT support ticket is passed to the network engineering group, one of the first steps in the troubleshooting process is to verify whether it is the network that is causing the problem or not. Especially when it’s not obvious to the naked eye that it’s the network’s fault. Sure enough, this is one of the top 5 uses cases of distributed network monitoring. I would like to expand a bit more on this specific use case since it costs time and causes unnecessary frustration during the time-critical window during which everyone is working to restore end-user services and user productivity.
The notion that the network is the first piece of the puzzle that causes slowness goes back to the day when the end-user had a thick client installed on their workstation and the network was the biggest uncertainty between them and doing their job. In today’s reality, those thick clients seem quaint and everything runs on a server somewhere out there (datacenter, AWS, Rackspace Cloud, etc). Things have changed.
DNS Failures
A DNS server failure is the quintessential example where nobody can access any internal applications and the network hasn’t even blipped. Although this can be easy to detect by experienced network and application engineers, the average Joe user gets the impression that the network is the problem. Also, it is almost pointless to try to explain that the DNS server went down to someone that doesn’t know and want to know (and shouldn’t know) what DNS stands for and what the DNS server does.
Applications vs. Network
The eternal conundrum… Here is where the network and application groups need the correct monitoring tool to distinguish between the two as fast as possible. The triage of the root cause is based on information collected by the help desk (unreliable), NAPM tools, and engineering experience/serendipity. However, some use cases stand out:
- If the problem is experienced only by users at a specific location, start looking for a network problem only if the users can’t access anything else on the network.
- If all users experience the problem it can be either the network or the application, and a decision tree like the one below can be followed during troubleshooting.
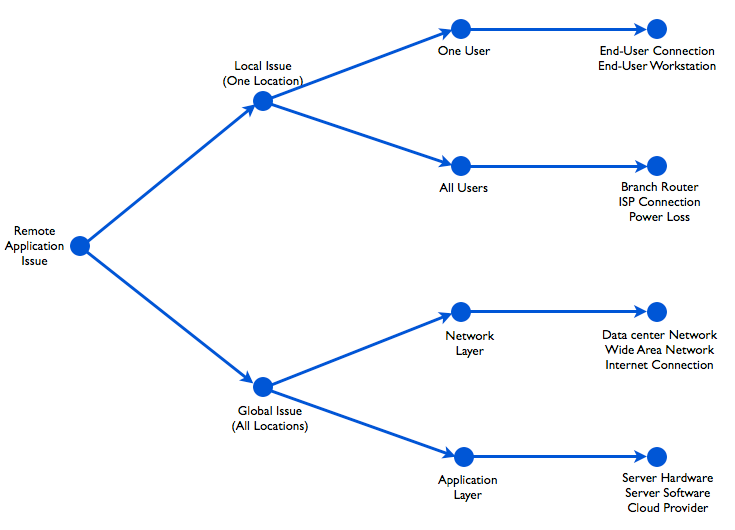
Decision tree to troubleshoot remote application issues.
A critical piece of information is, ‘Which users are affected and where they are located?’. The help desk collects this information, but often it is unreliable and it only includes data for the locations that users called in from. This is where an agent-based network monitoring tool that simulates users can give accurate information for every user location in two ways:
- Before troubleshooting: If the agents collect information before and after the beginning of the problem, then the troubleshooting team can have the precise information about the timeline of events and know if all or some applications experience the issue.
- During troubleshooting: If engineers need to run tests, such as an HTTP, traceroute, or Iperf, from each location that experiences the problem they can do it using the agents deployed there. This is an easy and effective way to declare that “It’s NOT the network!”
In IT culture, the network and applications groups are usually portrayed as having different interests, but that’s just a caricature. Being able to declare that the problem is not network related is just a first step towards finding the actual root cause. Actually, since the lines between the network and applications are getting blurrier and blurrier, the two groups are getting closer and closer. And monitoring tools need to follow suit in order to keep up with this trend.
If you want to discover how NetBeez helps network engineers reducing time to innocence, request a demo!




