In this post, I’d like to review a real event that highlights a couple of benefits associated with distributed monitoring of network infrastructure from the end user perspective. This use case happened for real the other week during the hot stage.
As you are probably already aware, the hot stage is a two week session where the NOC team and vendors meet to build and configure the network that will support Interop, which is taking place in Las Vegas from April 27th to May 1st.
So what did the BEEZ find at the hot stage? After having deployed one unit to each rack, we noticed a high number of failed HTTP tests on certain racks. For the sake brevity, I am not showing the data tables of HTTP test results associated with this graph.
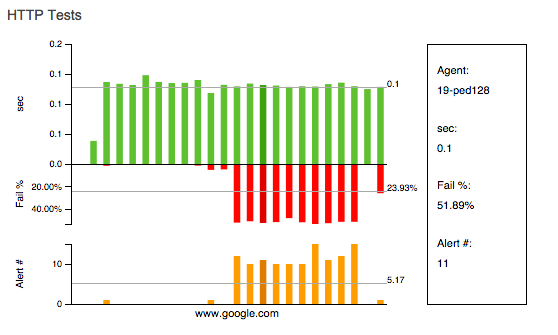
Each bar represents the average HTTP query time of an agent (green), including the percentage of failures (red) and the number of alerts generated (yellow).
If you look at the failed tests, some BEEZ reported a 50% failure rate for HTTP tests. The error code reported was “name lookup timed out”, which is generally a DNS-related issue.
![]()
The picture draw by the historical graph, in fact, was not very encouraging:
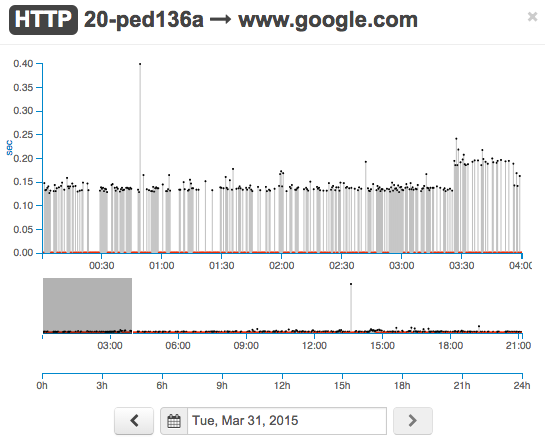
The question that we had was why only a subset of agents had so many failed HTTP tests with a DNS error code?
We quickly discovered that those agents resided on a particular subnet that had the same DHCP scope configured. The problem in that subnet was that the first of the two DNS servers reported in the DHCP lease was configured wrong (not existing). This was causing half of the HTTP tests run by those agents to time out.
We corrected the DHCP lease information and we immediately saw things improving:
![]()
The HTTP tests finally returned back to normal:
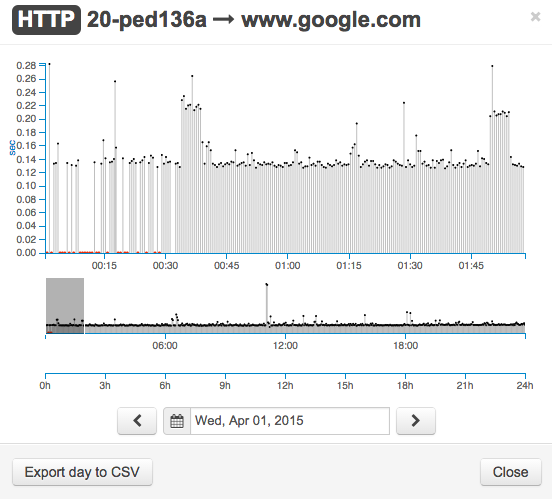
So how did the BEEZ help us during the troubleshooting process?
- We got data from multiple agents, confirming that the problem was extended to a common group of users that belong to the same subnet with the same DHCP scope configured
- The HTTP transactions from the client’s perspective allowed us verify whether the DNS servers were correctly configured or not
This type of monitoring is not only beneficial during the pre-deployment phase of a network, like what we did during the hot stage of InteropNet. Distributed network monitoring from the end user perspective can be also implemented during normal operations of the network. It gives the network administrator an edge for dealing with the aftermath of configuration changes to infrastructure components that could have a negative impact on services delivered to the end users.
I hope that this post was beneficial in demonstrating how distributed monitoring of network infrastructure from the end user perspective can help IT reduce complaint calls from end users as well as reduce time spent in the collecting information needed to troubleshoot and fix the problem.
I’d like to hear if you’ve ever experience a similar issue and the approach you took to troubleshoot and fix the problem.
Credits to Andrew Hoyos from Hoyos Consulting LLC for spotting the problem.