Post-Pandemic Networking
A report released by EMA on post-pandemic networking highlighting the state of remote work-from-home for enterprises. In that report, many interesting statistics and findings are mentioned, such as, which technologies organizations are using to extend their enterprise networks to employees’ homes, what network monitoring protocols and techniques they are using to support remote users, and some new trends (e.g. cloud adoption) that WFH has been accelerating. I encourage you to download and review the report as it’s free ($795.00 value elsewhere) to our readers and definitely worth your time.
Top Root Causes of Work-From-Home Troubles
One section that I found very interesting for practitioners is the one that recapped the root-causes of WFH user complaints. This is a super hot topic today, as we see at NetBeez, many organizations that need quick and reliable insights on root-causes of end-user experience. The reports highlighted the following root causes of work-from-home troubles, which is in line with what we hear from prospective customers. Here’s the list …
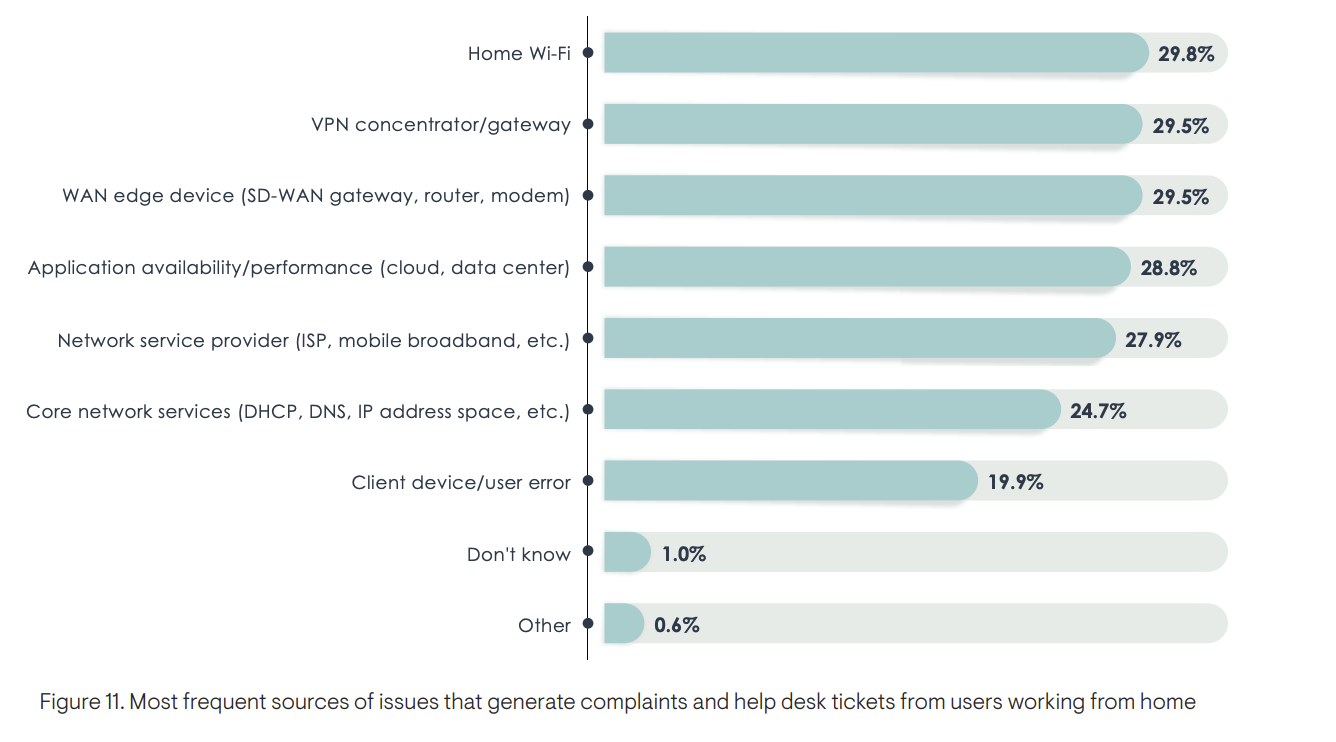
Figure 1.
The report also mentions one IT manager that took part in the survey and said that “Determining whether it is the ISP or local Wi-Fi is one of the tougher questions to answer. We might have an ISP that goes down or has peering issues with my ISP, and that’s hard to troubleshoot because ISPs are not talking to each other.” So how does NetBeez help IT managers and tech support stop wasting time chasing a needle in the haystack?
Let me describe with real examples how NetBeez helps IT Operations teams achieve operational excellence in tech support.
Root-Cause #1: Wi-Fi Metrics
Once you install a NetBeez remote worker endpoint, Wi-Fi metrics are collected and immediately transmitted to the centralized dashboard. From that moment on, an IT manager or help desk agent can inspect real-time and historical Wi-Fi metrics for any remote user that is running a NetBeez endpoint. This will allow the help desk to identify low signal or bad connections, as well as review locally available SSID and potential sources of interference. Check out the following screenshot taken from a macOS endpoint, which also reports the MCS index.
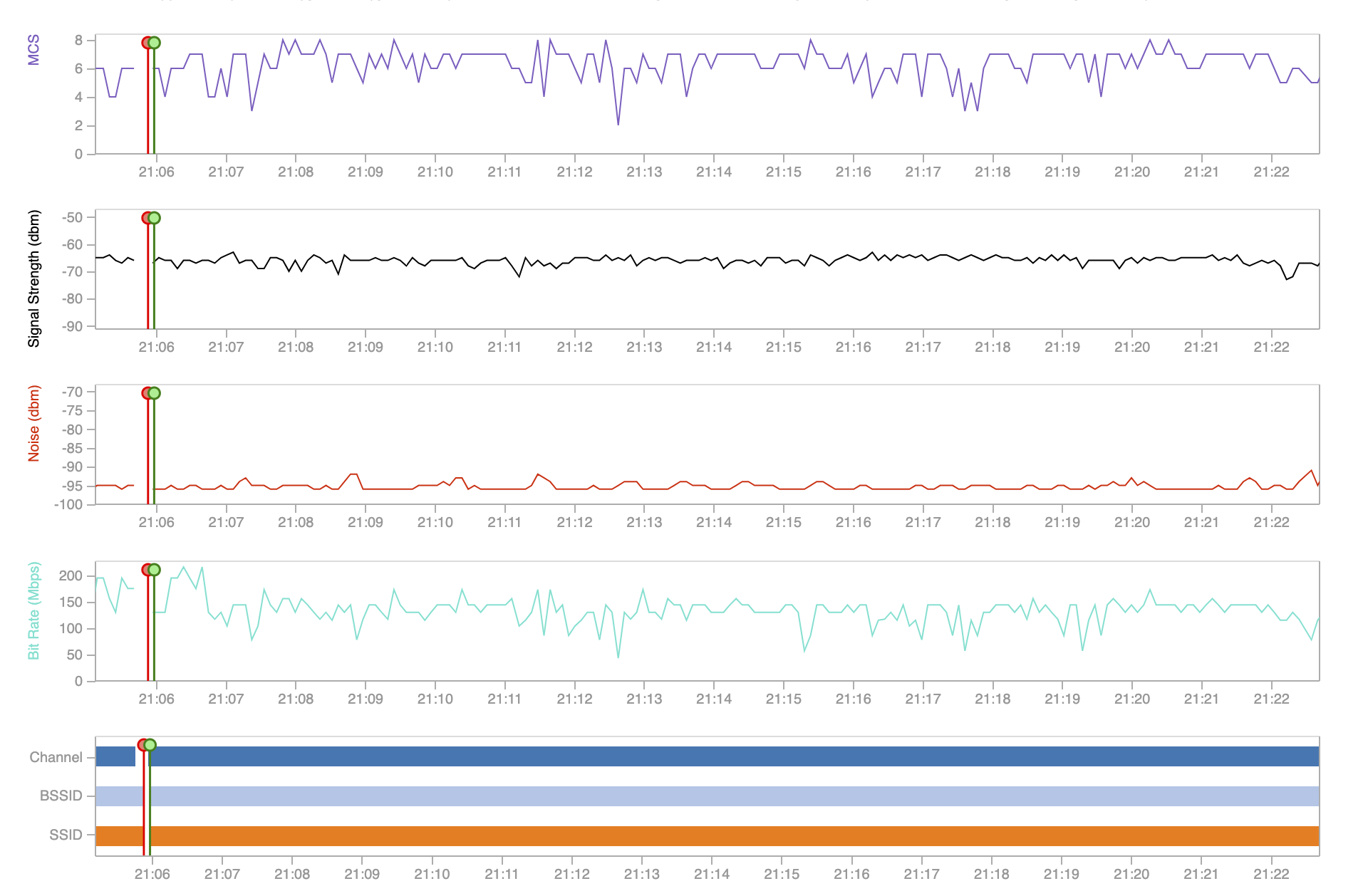
Root Cause #2: VPN Concentrator
Users that rely on a VPN connection to access enterprise applications hosted on-prem or in the cloud require the utmost VPN uptime and performance. Checking the status and performance of the VPN concentrator (e.g. CPU, Memory, etc.) itself is insufficient to troubleshoot all problems that remote users are experiencing. So how do you measure VPN performance from the end-user’s point of view? NetBeez does that by sending lightweight test traffic from the remote client to a destination beyond the VPN tunnel, constantly verifying VPN connectivity and performance. The dashboard will detect and report increases in packet loss or latency that have an impact on TCP throughput and VoIP call quality; NetBeez is also capable of estimating Mean Opinion Score, which is an important metric for call quality.
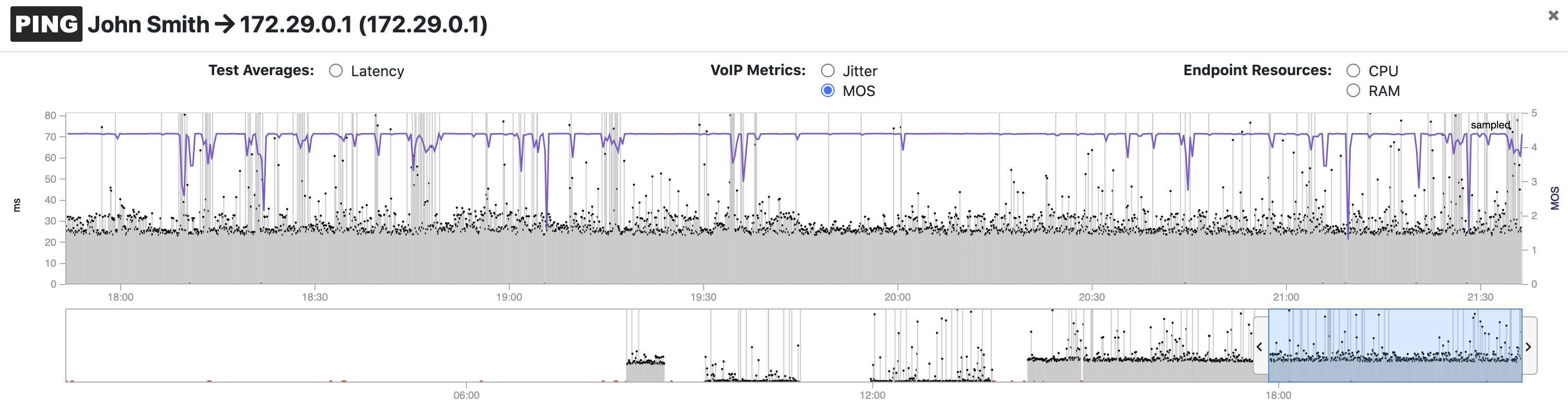
In the above screenshot, you can see a clear correlation between increase in latency and reduction of MOS value from a test performed across a VPN tunnel.
Root-Cause #3: SD-WAN Gateway, Router, Modem
Similarly to what I recommended in the above paragraph for VPN connections, also the performance with edge devices should be monitored with active telemetry and from the end-user perspective, via endpoints or network agents. By configuring ping tests that run every 5 or 10 seconds, such frequency will be key to gather granular and accurate data on latency and packet loss that help identify performance issues associated with those devices.
Root-Cause #4: Application Availability
How do you know if an application is actually running well or is having performance issues or even completely down. You can rely on resources such as the service provider’s status page, if they have one, down detector, sometimes even twitter … But is this really an efficient and proactive way to support your users?
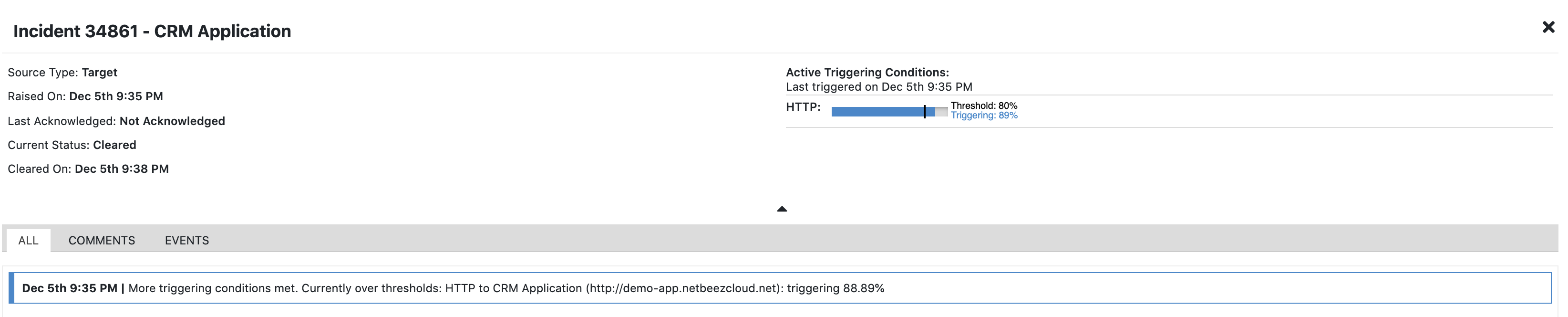
NetBeez provides an automated way to detect application outages (called target incidents) by analyzing in real-time connectivity and performance stats to that application from many remote users. If only one user is having application issues, then better check his network connectivity, etc. … but if all users can’t connect to an application, including cloud agents that monitor from AWS or Azure, then an application outage is the root cause. This is the power of distributed network monitoring, where the more endpoints you have and the richer the data that you can get about application performance. The following screenshots shows for example a CRM application is throwing many performance issues every hour or so:
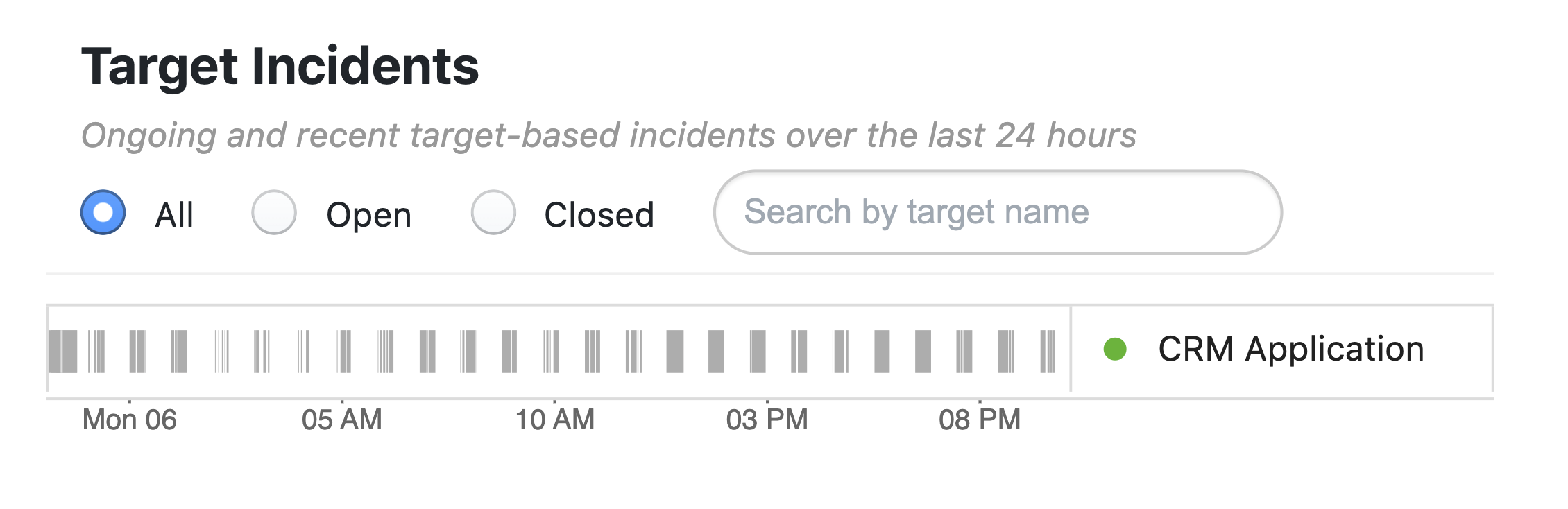
By further inspecting the data associated with the incidents, the root cause is the HTTP/S server.
Root-Cause #5: Network service provider
Sometimes, and pretty often in our experience for work-from-home users, the root-cause actually is the network. More specifically, the Internet Service Provider’s network.So how does NetBeez detect ISP issues? NetBeez accomplishes this with two functionalities.
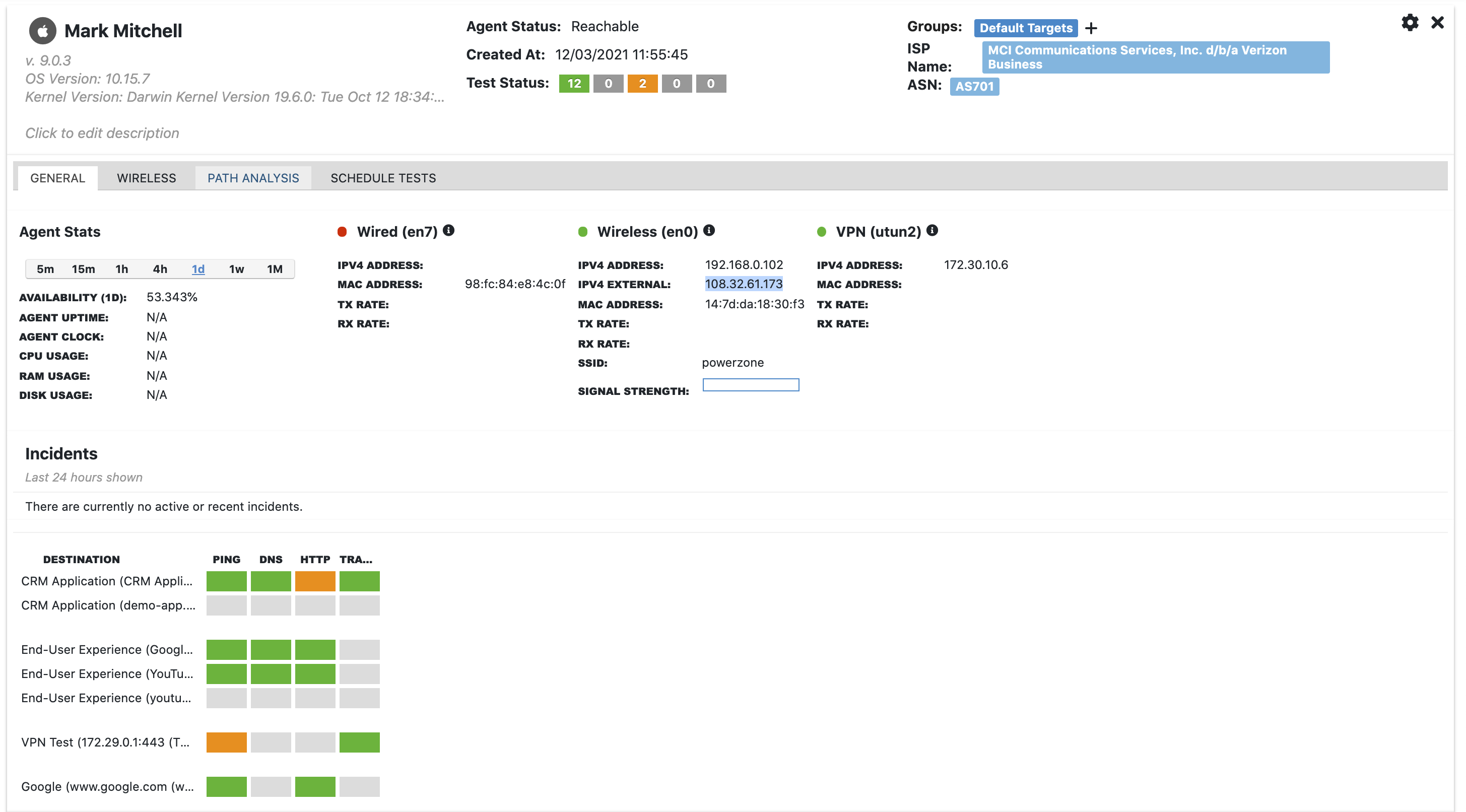
First, it automatically reports the ISP name and ASN that each agent is connected to. Thanks to this information, the network troubleshooter can filter agents by ISP or ASN and identify if alerts and incidents are associated with one or more specific providers. Take a look at the following screenshot here above, top right section …
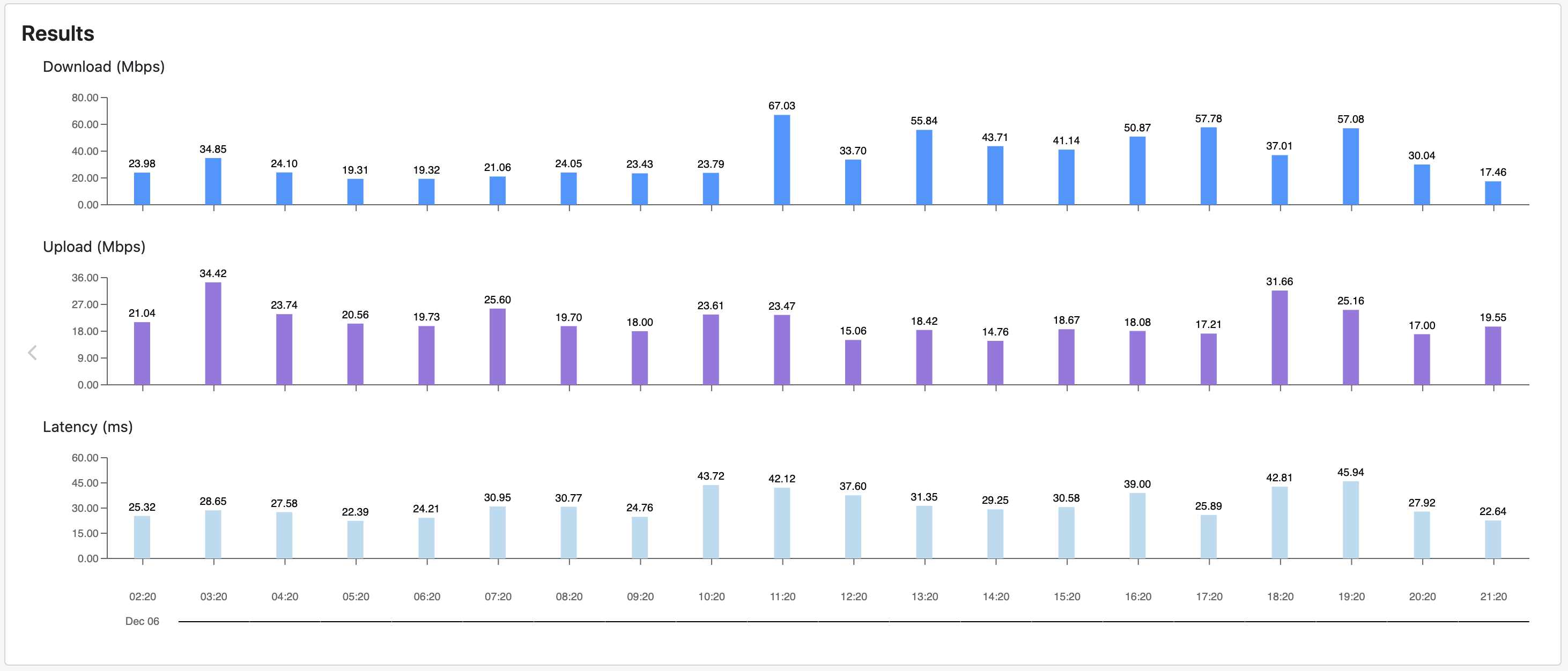
Second, NetBeez can instrument network speed tests to run every hour or whatever frequency the network manager deems necessary, even ad-hoc if needed. The following screenshot displays the results of regular network speed tests, both download and upload, run from remote work from home users.
Conclusion
Quoting a respondent from the survey that EMA Research interviewed to write this report: “If you don’t pay for [WFH] monitoring, you’ll hurt yourself,” Yes, indeed! I hope that this post helps the reader understand how a simple to use and deploy tool like NetBeez can make a huge difference for an enterprise, increase operational efficiency and reduce costs and efforts associated with hybrid work initiatives.




