Maximum Transmission Unit (MTU) is the hidden and all-important “bucket” that moves around all of the data we create and consume on an IP based network, such as the Internet. The often cursed (and almost always the last thing to be checked when troubleshooting a network problem) MTU lives in infamy as a foundational (but yet forgotten) piece of inter-networking lore.
What is it? MTU is the size of the largest protocol data unit (PDU) that a single network layer transaction can carry. That means, it is the size of the container that your data filters into as it moves around.
MTU Sizes
MTU has been the focus of academic study from networking scholars and innovators as well as ire and clenched fists from operational networking engineers. The issues with MTU are subtle and often esoteric. As there is no official “standard” for MTU size, per se, there are many de facto standards that are recognizable as accepted best practice. For example, 1500 is the standard internet MTU. 9,000 is the “Jumbo Frame” standard.
In the early days of long fat networks (LFNs), such as 10G Ethernet long-haul circuits, it was commonly mistaken that MTU created issues in large data transfers – spawning the phrase, “The bucket isn’t full, it’s the wrong size.” To further complicate deployment and troubleshooting, MTU configuration across multiple vendors (and in some cases, different products from the same vendor) can look vastly different.
MTU Implementations
Some vendors include the necessary overhead in their configuration and display (i.e. 1514, where 1500 is “standard”), and some do not. This causes additional heartburn in operational networks comprised of heterogeneous vendor hardware and can manifest in fun and exciting ways such as protocol failures and odd traffic behaviors. Much of this is based on hardware capability, as can be seen here in the same vendor with different MTU support, likely due to the underlying ethernet chipset.
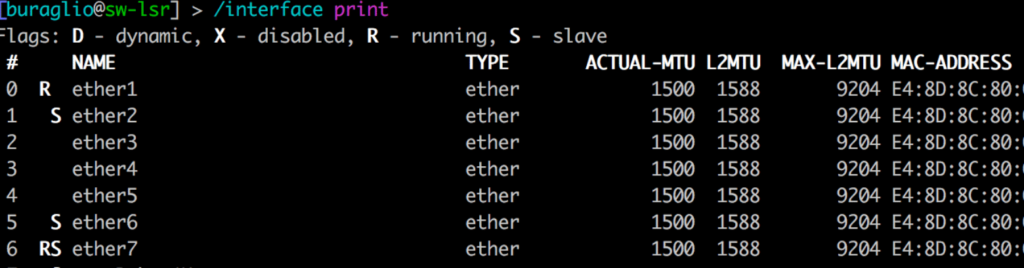
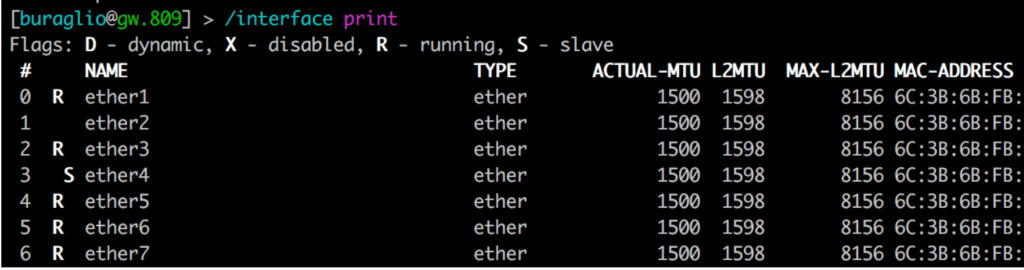
Figure 1 and Figure 2 (above) succinctly display the difference that hardware can make when defining MTU. Both devices are from the same vendor and run the same operating system. The devices have different merchant silicon based chips that support vastly different MTU values in hardware. This alone can cause significant heartburn when configuring links, and when combined with multi-vendor interaction, the need to truly understand it becomes fairly obvious.
Path MTU Discovery
There has been an attempt to abstract away some of the manual and convoluted nature of MTU with the inclusion of path MTU discovery (PMTU). This tool has been around for quite some time with the purpose of dynamically discovering the MTU of an arbitrary path. This was originally crafted with the intent of avoiding fragmentation and is supported on most, if not all, modern operating systems.
PMTU works across IPv4 and IPv6, but not in the same way; having an understanding of the full stack from end host to transport is fairly important when troubleshooting or creating an architecture. PMTU as a mechanism is widely unknown to most engineers since it operates at the host level and the equipment level for IPv4 (but not IPv6), and can, at times, complicate matters when certain protocols and mechanisms are filtered by middle-boxes such as firewalls or at Layer 3 edge points such as border routers. To further complicate matters, widely deployed protocols and transport mechanisms such as LTE, PPPoE, MPLS, and various VPN technologies require a larger header and therefore steal away from payload size when deployed across typical internet links utilizing 1500 byte MTU.
Given this high-level overview of MTU and the mechanisms surrounding it, it should obvious that this little, often overlooked tidbit can make or break network performance and in some cases cause complete connectivity failure and should be studied and well understood. There is a wealth of information about MTU available, including MTU troubleshooting guide we published.
About the Author
Nick Buraglio worked in the networking industry in varying roles since 1997. Currently works on the network planning and architecture team for a major international research network provider. Prior to his current role, Nick spent time working on network and security architecture in the higher education and research facility space, building regional networks for high-performance computing. Nick has also led network engineering teams at early regional broadband internet providers and provided strategy and guidance to many service providers around the world.
Nick specializes in service provider backbone networks but also dabbles in security, broadband technologies, instrumentation, monitoring, data centers, Linux, and everything in between. His personal blog is at https://www.forwardingplane.net and is full of esoteric ramblings and strong opinions.




